
告别photoshop?新的Google AI允许您通过询问修改图像。

多模式输出打开了新的可能性
拥有真正的多模式郊游可以在聊天机器人中开辟新的有趣可能性。例如,Gemini 2.0 Flash可以播放交互式图形游戏或用连贯的插图生成故事,维护角色并通过多个图像固定连续性。它远非完美,但是角色的一致性是AI助手的新能力。我们尝试了它,这很疯狂,尤其是当他从另一个角度提供的照片视图时。
用Gemini 2.0 Flash创建一个多图像故事,第1部分。
Google / Benj Edwards
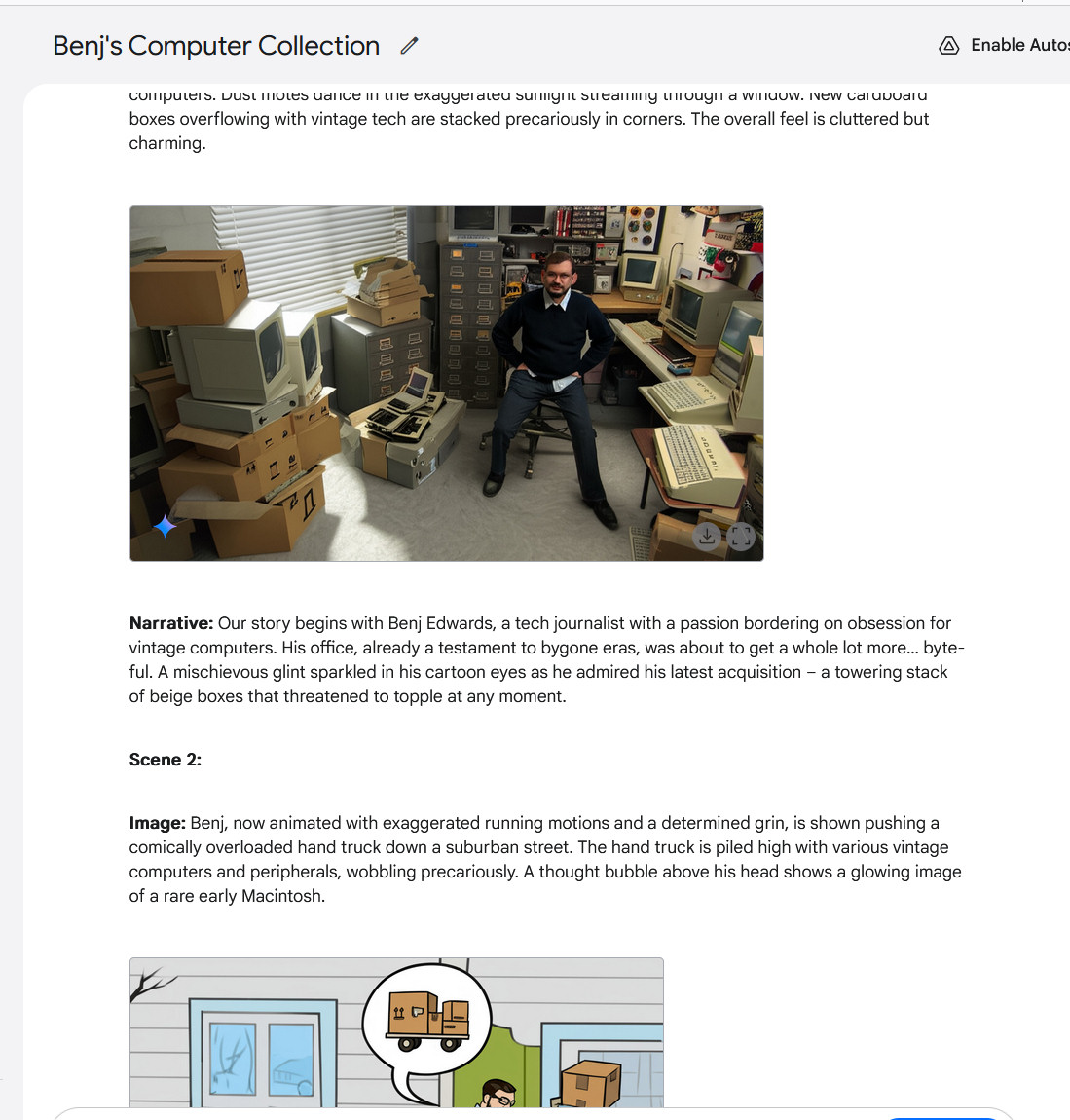
使用Gemini 2.0 Flash创建多图像故事,第2部分。请注意原始照片的替代角度。
Google / Benj Edwards
使用Gemini 2.0 Flash创建多图像故事,第2部分。请注意原始照片的替代角度。
Google / Benj Edwards
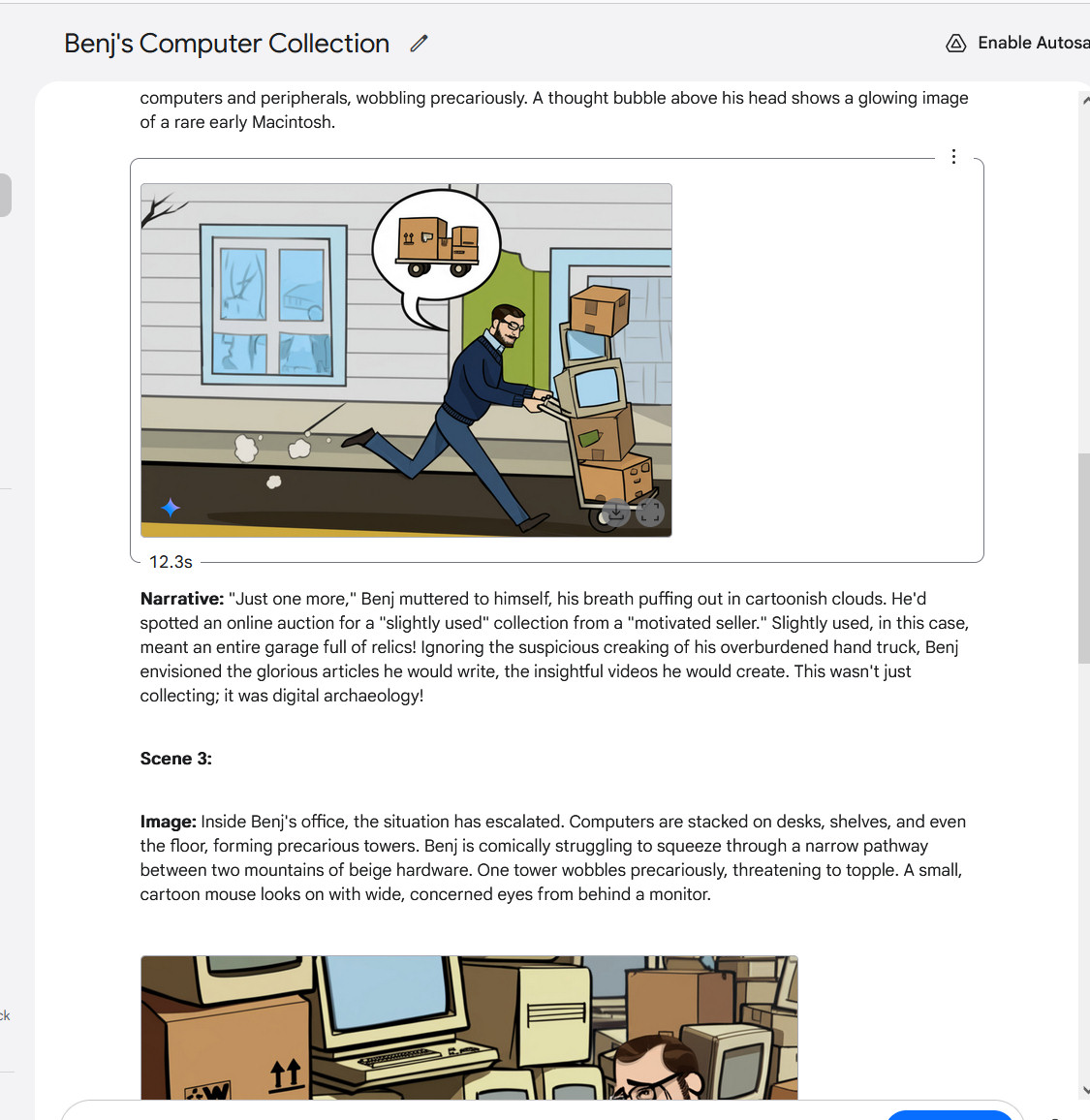
创建Gemini 2.0 Flash的多图像故事,第3部分。
Google / Benj Edwards
创建Gemini 2.0 Flash的多图像故事,第3部分。
Google / Benj Edwards
使用Gemini 2.0 Flash创建多图像故事,第2部分。请注意原始照片的替代角度。
Google / Benj Edwards
创建Gemini 2.0 Flash的多图像故事,第3部分。
Google / Benj Edwards
文本渲染代表了模型的另一个潜在力。 Google声称内部参考表明,Gemini 2.0 Flash在包含文本的图像过程中比“主要竞争模型”更好,这可能使其有可能适合使用集成文本的内容创建。根据我们的经验,结果并不是那么令人兴奋,但是它们是可以读书的。
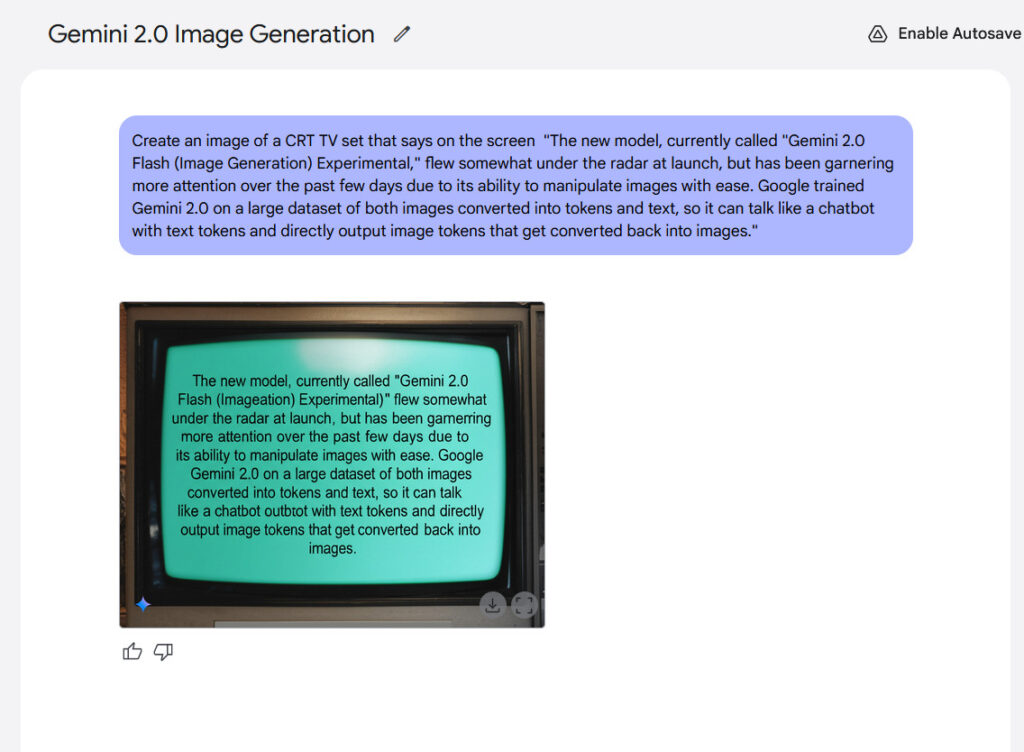
Gemini 2.0 Flash生成的图像中文本渲染的示例。
图片来源:Google / ARS Technica
尽管到目前为止,Gemini 2.0 Flash的差距存在差距,但真正的多模式郊游的出现在AI的历史上还是很值得注意的,因为技术是否继续改善。如果您想象未来,请说十年来,一个足够复杂的AI模型可以实时生成任何类型的介质 – 文本,图像,音频,视频,3D图形,3D打印物理对象和交互式体验 – 您本质上都有一个 Holodeck但是没有问题的复制。
返回现实仍然是多模式图像版本的“第一天”,Google认识到它。回想一下,Flash 2.0旨在是一种较小的AI模型,执行更快,更便宜,因此它没有吸收互联网的全部范围。所有这些信息在参数数量方面需要很大的空间,而更多的参数意味着更多的计算。相反,Gemini 2.0通过喂食有组织的数据集形成Google,该数据集可能还包括有针对性的合成数据。因此,该模型并不“知道”有关世界视觉视觉的所有事物,而Google本身说培训数据“广泛,一般,不是绝对或完整”。
这只是一种复杂的方式,即从图像中退出的质量不是完美的,但是。但是,随着培训技术的进步和计算成本降低,将来有很大的改进空间可以整合更多的视觉“知识”。如果我们在基于稳定扩散等扩散的AI图像发生器中看到的过程变成了某些东西,那么一天中期和流动,多模式图像输出的质量可以在短时间内迅速提高。为完全流畅的媒体现实做准备。



